Excel VLOOKUP 函数是最受欢迎的函数之一。VLOOKUP函数最经典的应用是:把A表的某列数据一一对应地写到B表中。这个功能相当于数据库中2个表的连接合并操作,这种应用在数据处理中十分广泛。
但在实际应用中,函数会返非预期的数据,让人感觉莫名其妙。如果数据集很大,不去一一核对结果的话,往往出错而不知,十分危险。本文探讨这个问题,并通过实际测试,给出问题的原因,并提供一些解决方案。
1 . VLOOKUP函数语法简介

函数的第4个参数,是可选参数,默认值为1(或TRUE),表示“近似匹配”。如果将该值指定为0(或FALSE),函数执行“精确匹配”操作。
2、实例(精确匹配模式)
下面通过一个实例来演示函数的功能,表中数据是虚拟的。A表是录取库,包含了考生的录取信息,B表是成绩库,无录取信息。现在要把A表中的录取信息写到B表中,VLOOKUP函数是实现该功能的首选。
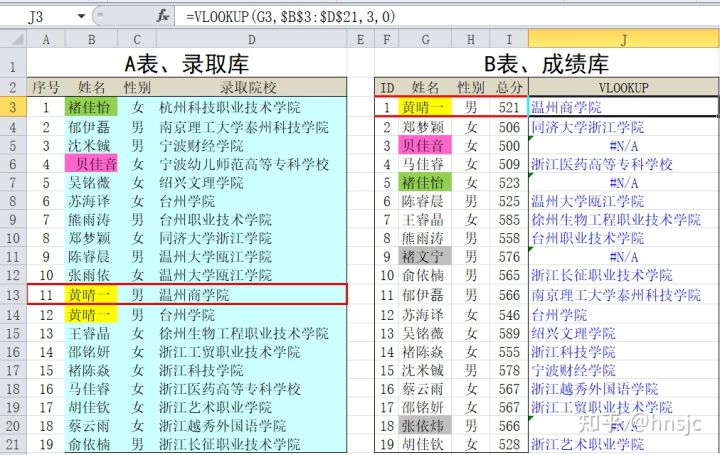
在J3单元格输入公式:=VLOOKUP(G3,$B$3:$D$21,3,0),对照函数语法,几个参数含义为:
- 第1参数G3,表示引用G3单元格的值(黄晴一),指定要要查找的值。
- 第2参数$B$3:$D$21,是待搜索的数据区域,即上图A表中湖蓝底色区域,共19行*3列,采用了绝对地址($)的引用格式。这里,数据区域的第1列必须是含有待查姓名的列。
- 第3参数3,表示返回该数据区域的第3列中对应行的值,即对应考生的“录取院校”信息。
- 第4参数0,表示精确匹配,即查找时必须完全匹配“黄晴一”,一字不能差。
“J3”单元格的计算结果是“温州商学院”,符合要求。然后把“J3”单元格的公式拖动到“J9”,就完成了“A表的录取信息写到B表”的操作。
上例中,存在一些问题,包括4项返回错误提示“#N/A”(表示“值不可用”),具体分析如下:
- 黄晴一:因A表中有2个“黄晴一”,函数匹配到第1个(这是默认操作)。所以使用VLOOKUP函数时,一般不用“姓名”作为参数1(即2个表的连接字段)去查找,因为姓名可能会有重名。可以用有唯一编码值的字段,如学号、身份证号去查找。
- 贝佳音:A表中是有此人的,匹配不到的原因是函数使用了“精确匹配”,而A表中的“ 贝佳音”多了一个前导空格,计算机不认为是相同值。解决办法是:将A表中姓名列中的所有空格替换为空,即在“查找内容”框中,按空格键输入一个半角空格,“替换为”框中不输入,代表什么也没有,按然按“全部替换”即可。
- 褚佳怡:造成不匹配的原因是B表中的褚佳怡有一个后导空格“褚佳怡 ”,电脑中粗看看不出来。解决方法同样是改用公式:=VLOOKUP(Trim( G7),$B$3:$D$21,3,0)。其中Trim函数可以清除前、后导空格。
- 褚文宁和张依炜:A表中确实无此2人,函数返回“#N/A”是正常的。
3、 实例(近似匹配模式)
参数4如果为“1”或“TRUE”,则表示“近似匹配”模式。仍以上例的相关数据来进行测试,在K3单元格中录入公式:=VLOOKUP(G3,$B$3:$D$21,3,1) ,再拖动填充到K19。
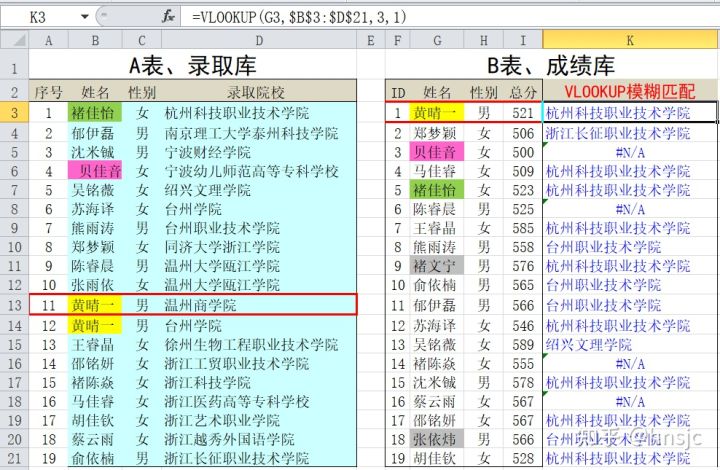
运算结果“一塌糊涂”,这哪是模糊匹配,分明就是“迷糊匹配”。那么问题出在哪儿?查函数使用说明,在近似匹配时,“必须按升序排列参数2(即数据区域)中的第一列的值,否则,VLOOKUP 可能无法返回正确的值“。
尝试对A表按“姓名”列进行排序后 ,再看K列的运算结果,发现大多数据已经正确,如下图。
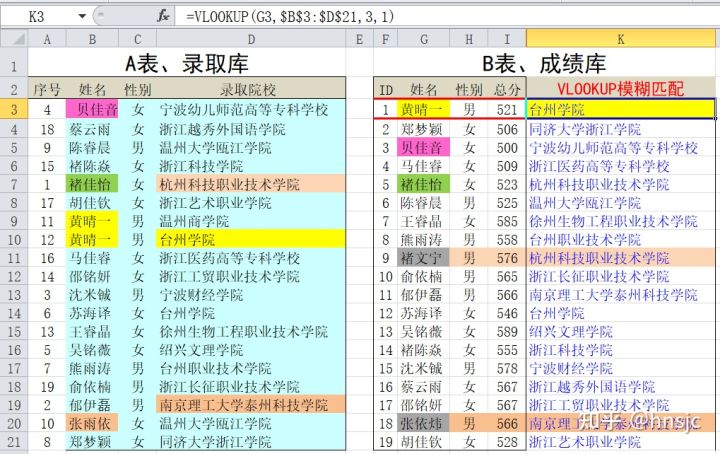
同样,运算结果中也存在一些问题,分析如下:
- 黄晴一:匹配到的是A表的第2个黄晴一(实际上是最后一个),这与参数4=0时不一样。
- 贝佳音:A表中为带有前导空格的“ 贝佳音”,看似函数返回了正确结果,实际不然。
- 褚佳怡:B表中的“褚佳怡 ”带有后导空格,函数也貌似返回了正确结果。
- 褚文宁、张依炜:应该是不返回值、给出出错提示的,但函数返回了一个错误的结果。
上述4个结果,不管正确还是错误,均是VLOOKUP执行某种规则所致。下图是网上关于VLOOKUP函数的一些说明,揭开了函数算法实现上的相关规则:
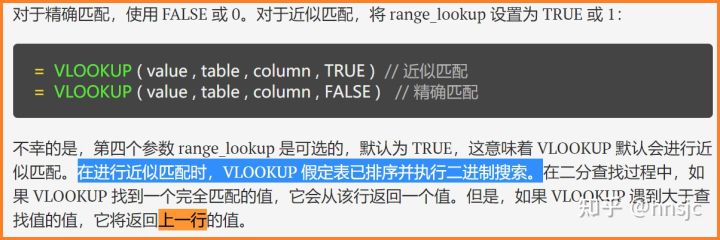
可见,如果不指定参数4,VLOOKUP函数默认使用“近似匹配”,这是一种“不幸”的指定,许多错误来源于此。在这种模式下,如果搜索到了完全匹配值 ,那就没问题,返回正确值。但如果未搜索到精确值,函数总是返回“大于查找值的值的上一行的值”,这十分拗口。如果对照上例中的4个结果值,逐一分析,可知是完全符合这一规则的:
VLOOKUP在近似匹配时,要求数据区域的第1列是升序排列,然后VLOOKUP总是查找“大于查找值的值”,比如A表中有2个“黄晴一”,VLOOKUP查到第一个,发现相等,再查第2个,还是相等,再查下一个“马佳睿”,大于“黄晴一”(这里是汉字拼音排序),然后函数返回上一个即第2个“黄晴一”所在行的值。再看“贝佳音”,按拼音序排在“蔡云雨”之前,带有前导空格的“ 贝佳音”之后,正好返回第一行的值,巧合正确。“褚佳怡”也是如此。而“褚文宁、张依炜”也可按此分析,得到的结果虽然不符合预期,但符合VLOOKUP的规则。
VLOOKUP函数这么做的目的是什么?看下个例子就明白了:
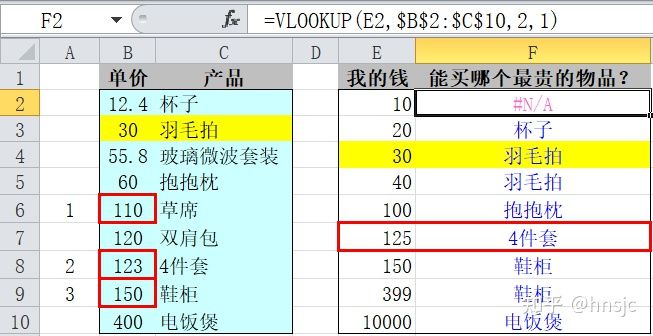
上图中,待搜索的值(即参数1)是一个数值,而不是文本。F列应用了近似匹配的VLOOKUP公式,观察运算结果,马上就可看出,正是“我的钱能买到的最大价格的商品是哪个?”的答案,丝毫不差。
我们来分析一下函数的算法,以第7行为例:125元能买哪个?图中用红框标示了相关单元格,函数采用“二分法”查找,A列列出了要进行的3次比较。函数首先取B列9行数据的中间值110(即二分法),然后执行比较125>110?结果为TRUE,说明目标值在110之后。再二分取后半部分的中间值123,比较125>123?结果为TRUE,再二分取150,比较125>150?结果为FALSE。经过这3轮比较,函数已经找到“大于查找值125的值为第9行的150”,满足这个条件后,函数不再继续查找,而是返回该行上一行即第8行的值“4件套”。
在计算机算法中,二分查找也叫“折半查找”,是一种高效的查找方式,但要求元素是有序排列。其时间复杂度为log(2)(n),n是行数。当n=100000时, log(2)(n)=16.6,可见程序最多执行17次判断就能找到目标值。如果逐一查找的话,最多需要判断10万次。
4 、 如何执行文本的模糊匹配?
“近似”不等于“模糊”,但在许多情况下,我们需要的是对文本的“模糊匹配”,该如何操作?
还是用实例1的数据,假设B表中的姓名丢失了第3个字,仅剩前2个,或者说B表的关键字是A表对应关键字的一部分,那就用下述公式:(公式中采用LEFT函数取姓名的前2字来模拟)
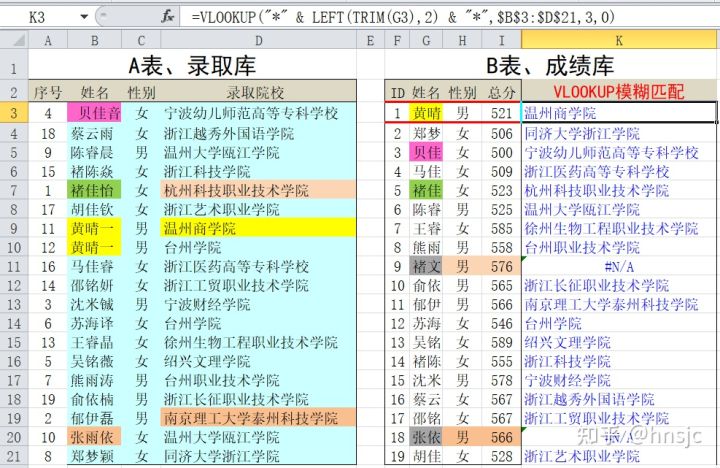
公式为:=VLOOKUP("*" & LEFT(TRIM(G3),2) & "*",$B$3:$D$21,3,0)。注意公式中,参数4还是用0,即精确匹配。而模糊查找的功能用参数1两边加通配符*来实现。
G3单元格的内容是“黄晴一”,在去空格后,取左2位,再前后各加上一个星号,变为 “*黄晴*”,来模拟2位字符的姓名,再去精确匹配查表。从本例来看,K列公式运行结果都是正确的。
但实际上,这跟数据集内容有关,如果A表数据中同时有“王振”和“王振宇”,当函数用“*王振*”去查找,匹配到的还是第1个,这种结果存在不确定性。
5、 大数据集应采用哪种匹配模式?
函数在近似匹配时使用的“二分查找法”十分效率,这对超大数据集的操作十分有用。经测试,在一个近10万条记录的实例中,2种模式用时相差2000多倍。
测试的数据集为:A表有70000行,B表有18000行。连接2表的列是一个11位宽度的文本,关键词均不重复。
首先使用精确匹配模式:=VLOOKUP(A2,[文件1.xlsx]表A!$A$2:$U$70000,7,0),并双击该单元格拖动柄,计算18000个公式,电脑运算了约1分钟之久。可大致计算一下函数执行的比较次数为:18000*70000/2~6.3亿次。如果对A表第1列进行升序排列,函数仍旧需要这么多时间,可见函数在精确匹配时,并不使用二分查找算法。
然后改用近似匹配模式:=VLOOKUP(A2,[文件1.xlsx]表A!$A$2:$U$70000,7,1),同样计算18000个公式,电脑几乎马上就完成运算,显示出结果。估算函数执行的比较次数为:18000*log(2)(70000)=18296*16.13~29万,比前面的6.3亿小了2100多倍,前面计算1分钟的话,本次仅需0.028秒。
当然,使用近似匹配方式,还是需要注意“近似”的问题。如果已知B表的记录在A表中都能找到完全匹配项,这无疑是一个好选择。
6、 使用VLOOKUP函数的一些注意事项
- VLOOKUP永远只能查找数据区域的第1列,返回该列或右边列的值,即“向右看”。
- VLOOKUP仅查找第一个匹配项。如果有多个匹配项,建议使用“数据透视表”。
- VLOOKUP的默认设置是近似匹配,这项“不幸”的设定能带来莫名其妙的结果。
- VLOOKUP不区分大小写。建议使用INDEX 和 MATCH 函数的组合公式。
- VLOOKUP引用数据区域时,需要使用绝对地址,否则拖动公式时会出错。
- VLOOKUP的数据区域插入一列后,可能需要修改公式的第3参数,否则会出错。
- ……
office的最新版本office365,已经使用XLOOKUP函数来代替VLOOKUP和HLOOKUP,功能更为强大,详见相关文档,不文不再赘述。